 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSearchQA: Bridging the Comprehensiveness Gap for Deep Research Agents
Jan 28, 2026We introduce DeepSearchQA, a 900-prompt benchmark for evaluating agents on difficult multi-step information-seeking tasks across 17 different fields. Unlike traditional benchmarks that target single answer retrieval or broad-spectrum factuality, DeepSearchQA features a dataset of challenging, handcrafted tasks designed to evaluate an agent's ability to execute complex search plans to generate exhaustive answer lists. This shift in design explicitly tests three critical, yet under-evaluated capabilities: 1) systematic collation of fragmented information from disparate sources, 2) de-duplication and entity resolution to ensure precision, and 3) the ability to reason about stopping criteria within an open-ended search space. Each task is structured as a causal chain, where discovering information for one step is dependent on the successful completion of the previous one, stressing long-horizon planning and context retention. All tasks are grounded in the open web with objectively verifiable answer sets. Our comprehensive evaluation of state-of-the-art agent architectures reveals significant performance limitations: even the most advanced models struggle to balance high recall with precision. We observe distinct failure modes ranging from premature stopping (under-retrieval) to hedging behaviors, where agents cast an overly wide net of low-confidence answers to artificially boost recall. These findings highlight critical headroom in current agent designs and position DeepSearchQA as an essential diagnostic tool for driving future research toward more robust, deep-research capabilities.
Scalable Semantic Querying of Text
May 03, 2018
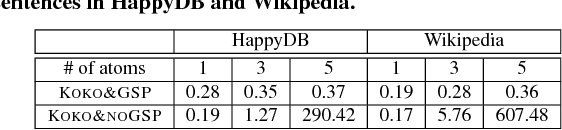
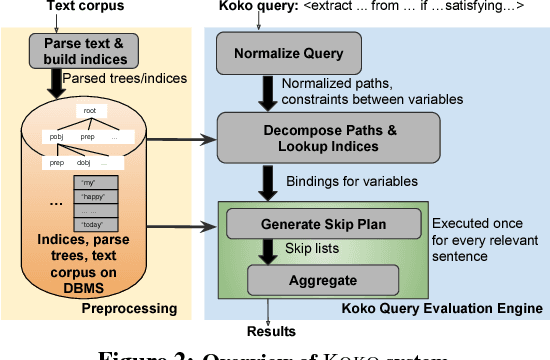
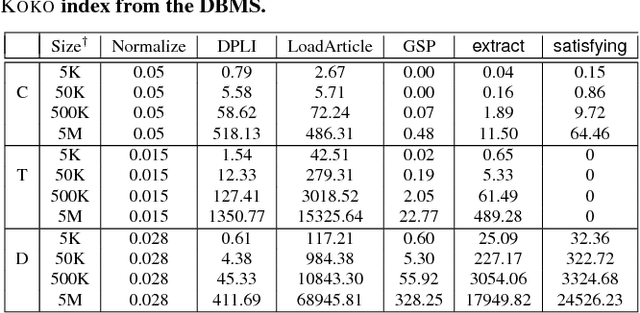
We present the KOKO system that takes declarative information extraction to a new level by incorporating advances in natural language processing techniques in its extraction language. KOKO is novel in that its extraction language simultaneously supports conditions on the surface of the text and on the structure of the dependency parse tree of sentences, thereby allowing for more refined extractions. KOKO also supports conditions that are forgiving to linguistic variation of expressing concepts and allows to aggregate evidence from the entire document in order to filter extractions. To scale up, KOKO exploits a multi-indexing scheme and heuristics for efficient extractions. We extensively evaluate KOKO over publicly available text corpora. We show that KOKO indices take up the smallest amount of space, are notably faster and more effective than a number of prior indexing schemes. Finally, we demonstrate KOKO's scale up on a corpus of 5 million Wikipedia articles.
A Lightweight Front-end Tool for Interactive Entity Population
Aug 01, 2017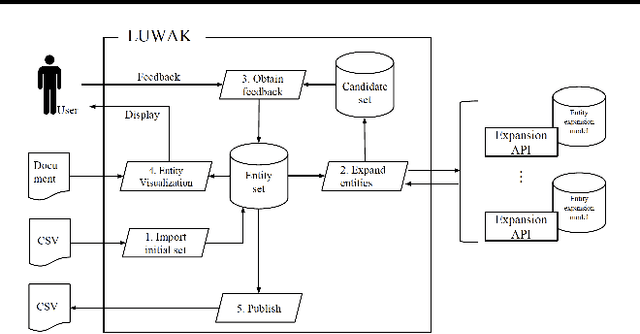
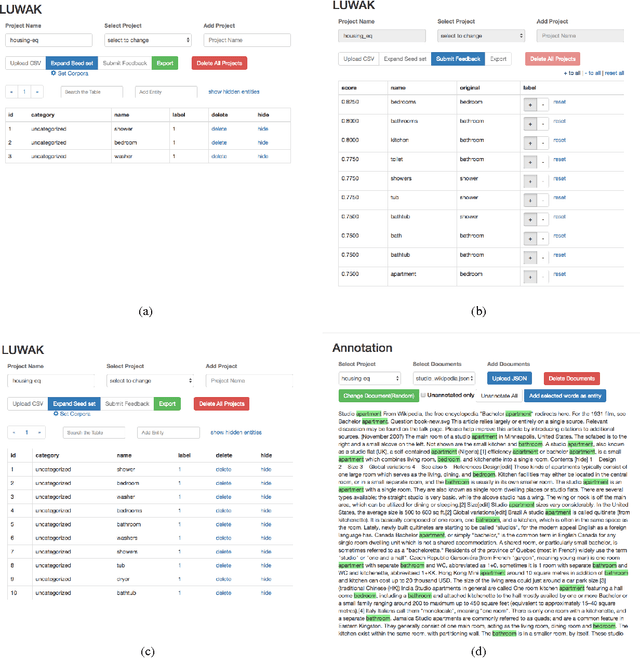
Entity population, a task of collecting entities that belong to a particular category, has attracted attention from vertical domains. There is still a high demand for creating entity dictionaries in vertical domains, which are not covered by existing knowledge bases. We develop a lightweight front-end tool for facilitating interactive entity population. We implement key components necessary for effective interactive entity population: 1) GUI-based dashboards to quickly modify an entity dictionary, and 2) entity highlighting on documents for quickly viewing the current progress. We aim to reduce user cost from beginning to end, including package installation and maintenance. The implementation enables users to use this tool on their web browsers without any additional packages --- users can focus on their missions to create entity dictionaries. Moreover, an entity expansion module is implemented as external APIs. This design makes it easy to continuously improve interactive entity population pipelines. We are making our demo publicly available (http://bit.ly/luwak-demo).
Knowledge Transfer for Out-of-Knowledge-Base Entities: A Graph Neural Network Approach
Jun 20, 2017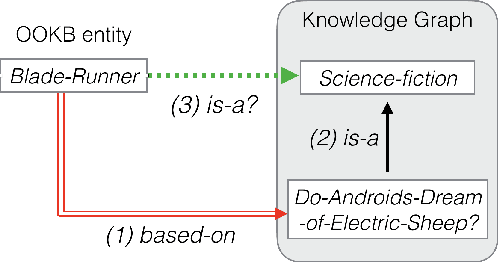
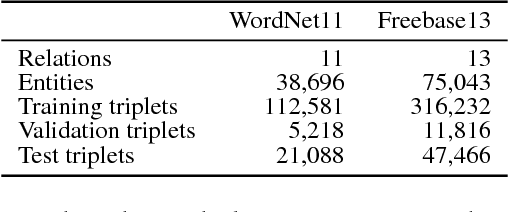
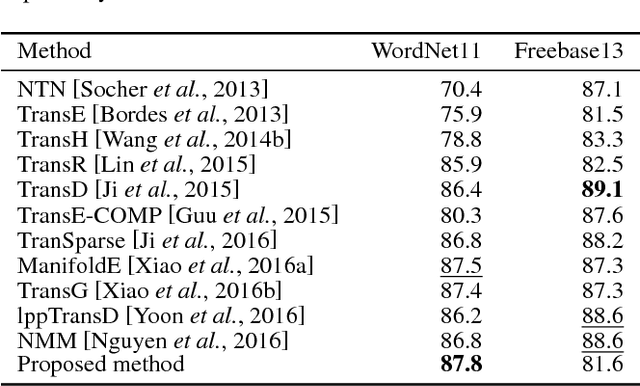
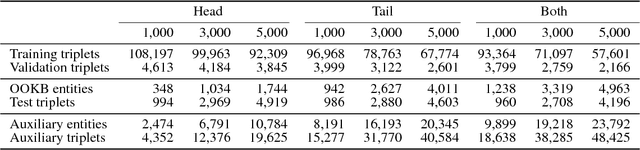
Knowledge base completion (KBC) aims to predict missing information in a knowledge base.In this paper, we address the out-of-knowledge-base (OOKB) entity problem in KBC:how to answer queries concerning test entities not observed at training time. Existing embedding-based KBC models assume that all test entities are available at training time, making it unclear how to obtain embeddings for new entities without costly retraining. To solve the OOKB entity problem without retraining, we use graph neural networks (Graph-NNs) to compute the embeddings of OOKB entities, exploiting the limited auxiliary knowledge provided at test time.The experimental results show the effectiveness of our proposed model in the OOKB setting.Additionally, in the standard KBC setting in which OOKB entities are not involved, our model achieves state-of-the-art performance on the WordNet dataset. The code and dataset are available at https://github.com/takuo-h/GNN-for-OOKB
Partition-wise Linear Models
Oct 31, 2014
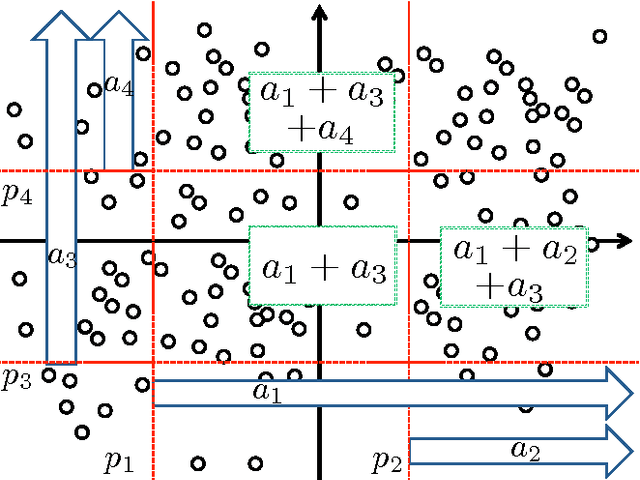
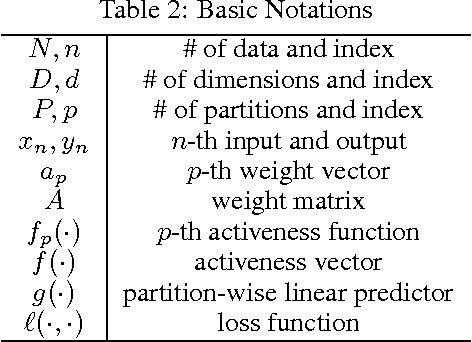
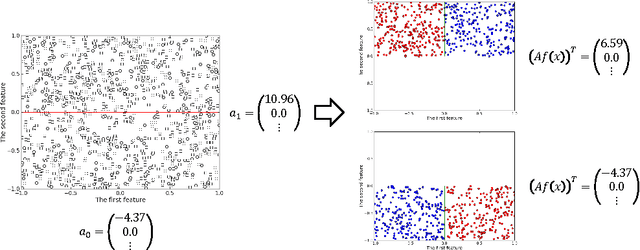
Region-specific linear models are widely used in practical applications because of their non-linear but highly interpretable model representations. One of the key challenges in their use is non-convexity in simultaneous optimization of regions and region-specific models. This paper proposes novel convex region-specific linear models, which we refer to as partition-wise linear models. Our key ideas are 1) assigning linear models not to regions but to partitions (region-specifiers) and representing region-specific linear models by linear combinations of partition-specific models, and 2) optimizing regions via partition selection from a large number of given partition candidates by means of convex structured regularizations. In addition to providing initialization-free globally-optimal solutions, our convex formulation makes it possible to derive a generalization bound and to use such advanced optimization techniques as proximal methods and decomposition of the proximal maps for sparsity-inducing regularizations. Experimental results demonstrate that our partition-wise linear models perform better than or are at least competitive with state-of-the-art region-specific or locally linear models.